GB2312、UTF-8、UNICODE编码(内码或码字)在线查询
GB2312、UTF-8、UNICODE编码(内码或码字)在线查询:http://www.2fz1.com/so/
根据字符集的编码规则及网上下载的一个码表,使用PHP简单写了一个编码查询工具,希望对大家有帮助!
该工具能帮助编码知识学习,起到一个更好的帮助作用。
个人原创工具,服务器性能有限,请勿非法访问PHP接口,谢谢!
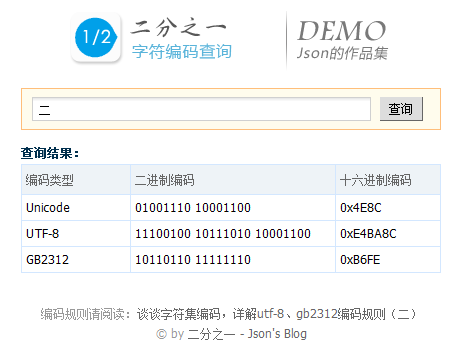
GB2312、UTF-8、UNICODE编码(内码或码字)在线查询:http://www.2fz1.com/so/
根据字符集的编码规则及网上下载的一个码表,使用PHP简单写了一个编码查询工具,希望对大家有帮助!
该工具能帮助编码知识学习,起到一个更好的帮助作用。
个人原创工具,服务器性能有限,请勿非法访问PHP接口,谢谢!
接上文:《谈谈字符集编码及gb2312、utf-8编码原理》
Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。 比如“二”字的unicode十六进制编码是:“4E8C”,对应二进制是:“100111010001100”共有15位,也就是说至少需要两个字节来存储;但对于unicode编码更大的字符,可能需要3个字节,甚至更多字节来存储。这样问题随之而来,在一段二进制流中如何区分这个字符是3个字节,还是6个字节呢?UTF-8就是unicdoe其中一个实现方式!注意只是其中一个,还有utf-16、utf-10等等…
使用1-4个字节来存储一个字符,最大的特点是可变长度。
编码规则:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
如下表所示:字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
——————–+———————————————
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx (可填11位unicode码)
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx (可填16位unicode码)
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx (可填21位unicode码)
还以“二”(100111010001100)为例,依上表可知“二”在UTF-8编码中为三个字节使用格式1110xxxx 10xxxxxx 10xxxxxx,从最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了 11100100 10111010 10001100(红色加粗为补0)即十六进制为“E4BA8C”,这个编码即为“二”的UTF-8编码。
GB2312中对所收汉字进行了“分区”处理,每区含有94个汉字/符号。这种表示方式也称为区位码。
01-09区为特殊符号。
16-55区为一级汉字,按拼音排序。
56-87区为二级汉字,按部首/笔画排序。
10-15区及88-94区则未有编码。
每个汉字及符号以两个字节来表示。第一个字节称为“高位字节”,第二个字节称为“低位字节”。 “高位字节”使用了0xA1-0xF7(把01-87区的区号加上0xA0),“低位字节”使用了0xA1-0xFE(把01-94加上0xA0)。例如“啊”字在大多数程序中,会以0xB0A1储存。(与区位码对比:0xB0=0xA0+16,0xA1=0xA0+1)。
http://www.2fz1.com/so/ (本站原创工具,请勿非法访问)
比特位即bit,是计算机最小的存储单位。以0或1来表示比特位的值。 Byte是字节数,bit是位数,在计算机中每八位为一字节,也就是1Byte=8bit; Byte和bit都翻译成比特,俗称大B(Byte)和小b(bit)
从GB2312-1980编码开始,汉字都是采用双字节编码。为了与系统中基本的ASCII字符集区分开,所有汉字编码的每个字节的第一位都是1。例如:“啊”字的编码为0xB0A1。(二进制:10110000 10100001) GB2312的汉字编码规则为:第一个字节的值在0xB0到0xF7之间,第二个字节的值在0xA0到0xFE之间。
GB12345和GB13000是对GB2312-1980的扩充,所有已经包含在GB2312中的汉字编码不变,另外增加更多的码位。其编码规则大致为:第一个字节的值在0×81到0xFE之间,第二个字节的值在0×40到0xFE之间。由于GB13000是对GB2312的扩展,所以也被成为GBK。
UTF-8编码是一种目前广泛应用于网页的编码,它其实是一种Unicode编码,即致力于把全球所有语言纳入一个统一的编码。
UTF-8用来存储字符串所对应的Unicode的码点,在UTF-8中,0-127之间的码字都使用一个字节来存储,超过128的码字使用2,3甚至6个字节来存储。
所以UTF-8并不是我们所习惯认为的,一个中文两个字节,在UTF-8中,中文一般占三个字节,对于特殊字符可能占更多的字节。
关于Unicode编码的相关知识,请搜索阅读《每个程序员都绝对必须知道的关于字符集和Unicode的那点儿事(别找借口!)》这篇文章
Unicode官网:http://www.unicode.org/
PHP中unicode编码演示:
<?php
@Header('Content-Type:text/html;charset=utf-8');
$res = array('msg'=>'欢迎光临');
$res = json_encode($res);
echo $res;
?>
运行后结果:
{"msg":"\u6b22\u8fce\u5149\u4e34"}
\u代表的是unicode,后面的数字为16进制,6b22代表汉字:欢(1101011 100010)
html:
<meta http-equiv="Conent-Type" content="text/html" charset="utf-8">
PHP:
@Header('Content-Type:text/html;charset=utf-8');
前提是PHP环境要提供iconv支持。
iconv("GB2312", "UTF-8",$str);